Less Documentation, More Signal
A year ago I would have praised a project with a 200-page wiki, detailed onboarding guides, and architecture docs covering every microservice. Thorough documentation was a mark of a well-run engineering team.
I don't think that anymore.
What Changed
Generating text became free. Any LLM produces pages of plausible-looking documentation in seconds. An intern with ChatGPT writes a 20-page architecture overview before lunch. It reads well. It has diagrams. It covers edge cases you haven't thought of yet.
And that's the problem. The text looks real. It passes a glance review. But it's noise shaped like signal. Quantity of documentation stopped being a proxy for quality the moment a machine could produce unlimited quantities of it.
When anyone can generate a 200-page wiki in an afternoon, the 200-page wiki tells you nothing about whether the team understands their system. The only thing that still signals understanding is compression: can you state what matters in 30 lines? If you can't, you probably don't know what matters.
On the other side of the same coin: LLMs read your docs now. Not metaphorically. Claude Code loads your CLAUDE.md, your cursor rules, your README into its context window before writing a single line of code. Every token of documentation competes with the actual code and specs the model needs to do its job. Bloated docs don't just waste human attention anymore. They waste token budget and degrade AI output.
I started trimming docs to save that budget. Ruthlessly. A 500-line CLAUDE.md became 40 lines of pointers. Architecture specs lost their rationale paragraphs, kept only requirements and constraints. Onboarding guides disappeared entirely; the rule files and folder structure became self-documenting.
The surprise: human developers on the team started navigating faster too.
The Old Contract Was Broken Anyway
The promise of comprehensive documentation was always fragile. A 200-page wiki has one critical failure mode: staleness. Somebody changes a service, the wiki doesn't get updated, and now the docs actively lie. The more documentation you have, the more surface area for rot.
People learned to distrust long docs. They'd read the first paragraph, then go look at the code. The docs existed to make the project look professional, not to actually transfer knowledge.
Short docs can't hide rot as easily. When your entire architecture spec is 30 lines, a stale line is obvious. When it's 30 pages, nobody notices the paragraph on page 17 that describes a service you decommissioned six months ago.
Where Docs Should Live
The shift isn't "no documentation." It's "documentation where you expect it, in the form you need it."
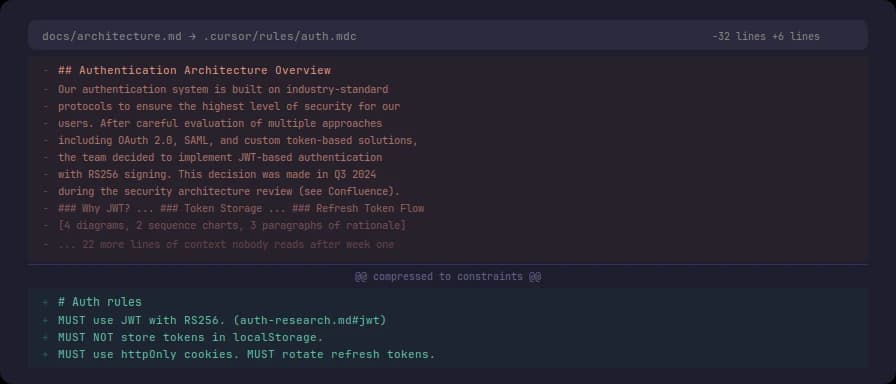
A cursor rule file at .cursor/rules/auth.mdc that says "MUST use JWT with RS256, MUST NOT store tokens in localStorage" does more work than a Confluence page titled "Authentication Architecture Overview" with four diagrams and three paragraphs of context nobody reads after the first week.
The rule file is:
- Co-located with the code it describes
- Consumed by both humans and LLMs
- Verifiable (grep the codebase for violations)
- Short enough that staleness is immediately visible
The Confluence page is none of these things.
Compressed Does Not Mean Cryptic
The most common pushback: "If you compress everything, new people won't understand it."
This turns out to be wrong in practice. "MUST validate input before processing" is clearer than "You might want to consider validating the user input before processing it, as this could potentially help prevent issues down the line." The first version is shorter and more precise. And if a junior developer doesn't understand what "validate input" means in this context, they ask an LLM right there: "what validation does the architect mean here?" That conversation gives them the domain knowledge they need anyway. The verbose version spoon-feeds an answer they forget by next week. The compressed version forces a learning moment.
I wrote about this distinction in detail in Principle of Parsimony in Context Engineering. The short version: parsimonious text removes noise, not meaning.
A mental exercise to calibrate the right volume:
Take your entire documentation corpus. Feed it to an LLM with one prompt: "What is the essence here?" The summary it returns is roughly the volume your documentation should have been in the first place. Everything the model discarded to produce that summary was noise you were maintaining, versioning, and paying people to keep current.
This isn't a literal prescription. It's a compass. If your docs are ten times longer than what an LLM considers essential, nine-tenths of your documentation effort is overhead.
The Framework That Emerged
After months of cutting docs across multiple projects, a pattern solidified:
Put docs where the tool looks. CLAUDE.md in the repo root. Cursor rules in .cursor/rules/. README.md in each significant directory. Not in a separate wiki, not in Notion, not in a shared drive nobody bookmarks. For larger projects with multiple repositories, a dedicated documentation repo works, but under the same rules: compressed, cross-linked, with a named person responsible for relevance audits. The moment documentation has no owner, it rots.
Use directive vocabulary. MUST, SHOULD, MAY, DO NOT. Not suggestions, not recommendations, not "best practices." Directives that a human can follow and a linter can check.
Monitor for relevance. Docs are not write-once artifacts. Every rule, every spec, every instruction needs periodic review: is this still true? Does this still matter? If the answer is no, delete it. Not archive it, not move it to a "deprecated" folder. Delete.
Constrain, don't describe. The best documentation is a system of constraints. A rule file that says "DO NOT use any ORM except SeaORM" is more useful than a page explaining why SeaORM was chosen. The constraint prevents mistakes. The rationale is a different document. If SeaORM was picked after a formal evaluation, that evaluation lives in a research folder or an ADR (Architecture Decision Record), and the rule links to it. One line: "DO NOT use any ORM except SeaORM (decision context)." The link exists for the rare case when someone needs to revisit the reasoning. In the overwhelming majority of interactions, both human and LLM, the motivation is irrelevant. They need the constraint, not its backstory.
The Parsimony Accident
I started this as a context budget exercise. The context window is finite. Every token spent on documentation is a token not spent on code, specs, examples, or conversation history. Less noise in context means better model output, fewer hallucinations, longer useful sessions.
But the practice revealed something: text sufficient for an LLM to understand a codebase is sufficient for a human too. The model doesn't need your narrative about why you chose PostgreSQL. It needs "MUST use PostgreSQL 15+, MUST use pgvector for embeddings." And so does the human.
This is how the principle of parsimony formed. Not as an abstract theory, but as a side effect of trying to fit more useful context into a fixed token window. The economics forced the clarity. The clarity turned out to be the real value.
What This Looks Like in Practice
One of the projects I work on has 32 repositories and ~41,000 lines of documentation total. When an agent starts a task in one service, it loads that service's CLAUDE.md and cursor rules. Typically 100-200 lines. Behind them sit the other 41,000 lines of specs, architecture docs, research notes across the project. A script assembles relevant pieces via traceability links when a task requires deeper context. By default, it doesn't.
The context window is finite; the documentation corpus grows with the project. Without parsimony, and writing less as one of its core aspects, every task would compete with thousands of lines that have nothing to do with it. Compressing the default context isn't a nice-to-have. It's arithmetic.
The numbers above were counted by Claude at my request.
Writing Less Is Harder
Writing less documentation is harder than writing more. Anyone can dump knowledge into a wiki page. Compressing that knowledge into 30 lines of rules that are precise, verifiable, and sufficient requires you to actually understand what matters.
Most documentation is written to reduce the author's anxiety, not to help the reader. "I documented everything, so if something goes wrong it's not my fault." Parsimonious documentation requires you to decide what matters and accept responsibility for leaving the rest out.
That's uncomfortable. It's also better engineering.
This entire article as an instruction set:
(1) Co-locate docs with code: CLAUDE.md in repo root, rules in
.cursor/rules/, README.md per directory. Large projects: dedicated doc repo, same rules, named owner for relevance audits. (2) Use directive vocabulary: MUST, SHOULD, MAY, DO NOT. (3) Write constraints, not descriptions. Rationale goes in separate decision records, linked from rules. (4) Delete stale docs. DO NOT archive. More docs = more surface for rot. (5) Default context MUST be small: only CLAUDE.md + rule files load automatically. Deep context assembled on demand by a deterministic script via traceability links, not by agent's choice. (6) Write less. LLM-generated text is noise shaped like signal; volume is not a proxy for quality. If you can compress it, the original was too long. (7) Text sufficient for LLM is sufficient for human. Unclear points are clarified by asking the LLM directly. (8) Writing less is harder than writing more. It requires understanding what matters and deciding what to leave out. Calibration: feed your doc corpus to an LLM with "what is the essence?" — the answer approximates your target volume. Reference: Principle of Parsimony.