Five Levels of AI-Agent Adoption in Software Development Teams
Everyone uses AI coding agents differently. Some copy-paste from ChatGPT. Some run fully autonomous pipelines. I see five distinct levels, and knowing where you are tells you what's next.
This comes from our partnership (ForEach Partners): over 100 people, 12 active projects. Some products haven't hit the market yet. Others have been in production for over a decade.
Where this comes from
Most of what I know comes from colleagues. Personal conversations, meetups, conferences. Some projects I join as a consultant and see firsthand what's going on inside.
The teams I'm talking about are small to mid-size. Solo developers, 3-4 person teams, up to 30-person squads. Budgets from $10,000 for an entire project to $100,000 per month. The products we build: AI-based customer support services, alternative UI layers powered by LLMs, prospecting and outreach tools, HR platforms, fintech (payment systems, some touching crypto), video-on-demand, VoIP systems, dating apps, and custom CRM/ERP solutions.
My other source is the internet. Hacker News, LinkedIn, Reddit. When someone's observations match what I see in practice, I trust their judgment more. Many ideas we've implemented came from these communities.
Where I can back a claim with data, I do. But this field moves fast and formal studies often don't exist yet. Some estimates below are mine. I flag those.
I write about what I see with my own eyes. I don't claim to speak for the entire software industry. The only thing I can say with confidence about the industry as a whole is that nobody really knows what's happening or what comes next.
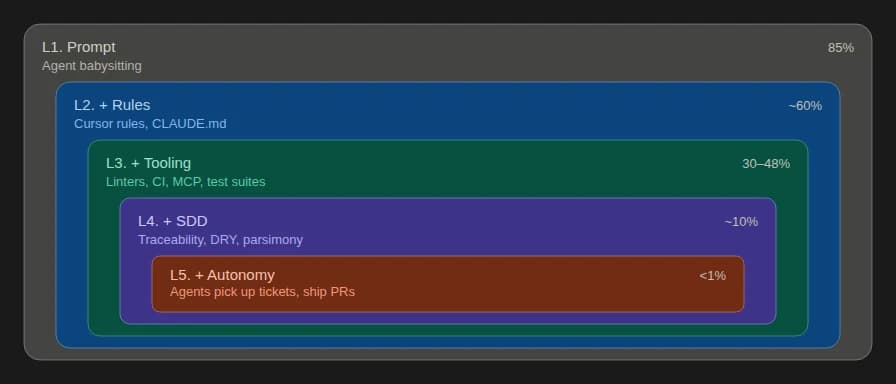
The five levels
I group everyone working with AI tools today into five natural maturity levels. Individual developers and entire teams pass through these stages. You can only move to the next level naturally, by hitting the limitations of your current one.
This classification is mine, but similar models exist. Everyone sees a progression from ad-hoc prompting toward autonomous agents. The differences are in where you draw the lines.
L0. Reference mode
You talk to the agent like a reference book. Ask a question, get an answer, go use it. Stack Overflow, but friendlier.
I numbered this zero because it's not really a level. Everyone starts here. But copy-pasting from a chat into your IDE gets old fast.
L1. Agent babysitting
Every developer I know has tried this. Hundreds of people. The JetBrains 2025 survey confirms: 85% of developers regularly use AI tools for coding.
You delegate tasks to agents. Write a prompt, get a result, review, correct, repeat. Until something decent comes out or the system falls apart.
This is where most vibe coders live. By "vibe coders" I mean people who can't evaluate the quality of what the LLM generates. Their projects hold together only while the codebase stays small. GitClear's study of 211 million lines found an 8x increase in duplicated code and churn rising from 5.5% to 7.9% in AI-assisted projects. In my experience, without rules the codebase starts resisting around a few thousand lines. Few stay here long.
L2. Agent with rules
When a developer stops being able to control the output through prompts alone, they keep having to repeat themselves: format user messages like this, load config values that way, use pnpm not npm. So they formalize it into rules. Cursor rules, CLAUDE.md files, and similar mechanisms.
This is also where vibe coders show up. The more advanced ones reach for rules too, often without understanding them. They just download someone's rules file from the internet. But poorly written rules can actually make output worse than having no rules at all.
Addy Osmani points out that auto-generated AGENTS.md files restate what's already in the code. Noise, not signal. The most effective rule files are surprisingly small. I wrote more about this in Less Documentation, More Signal.
Good, concise rules push the ceiling much higher. But a ceiling still exists. It appears when you cram everything into rules: functional requirements, architectural decisions, infrastructure constraints. At some point no LLM can hold them all in context. Some get ignored. You can't control which ones.
L3. Agent with tooling
When asking the agent to "do it right" isn't enough, deterministic tools enter the picture. Compilers, linters, test suites, regex checks. Browser MCP so the agent can debug the app without you. The agent deploys to staging, fixes CI, talks to GitHub through CLI tools, interacts with issue trackers.
Surround the agent with hard constraints, and it has to produce a quality solution. The developer's job shifts from writing code to selecting tools and sequencing the work. Delegate as much as possible to deterministic logic; leave the LLM only the creative parts.
Most developers who actively use agents are here right now. The Stack Overflow 2025 survey shows 84% use or plan to use AI tools, but 52% don't use agents or stick to simpler tools. The agent-powered pool is roughly 30-48% of the total.
You can build complex software this way. But it requires a senior specialist constantly present: setting tasks, managing the flow, reviewing results. One person handles it fine. With teams, coordination challenges pile up.
L4. Agent with SDD
This is where our partnership teams work right now. We're close to moving to the next level, since this one is already fully under control.
The tooling stays the same: rules, instruments, proper prompting. What changes is the introduction of a systematic approach to managing agents, specifically how you build context for each task.
SDD (Spec-Driven Development) gained momentum in 2024-2025. Thoughtworks calls it "one of 2025's key new AI-assisted engineering practices." GitHub, Amazon, and others have released SDD toolkits and entire IDEs built around the approach.
The core of SDD is traceability. Everything in the code is tagged so agents can see connections between artifacts. When implementing password reset, you assign an identifier like FR-AUTH-PASSWORDRESET. That ID appears in the OpenAPI spec, the backend handler, the frontend route, and every test. The agent finds the right context for a task and considers all aspects when developing or extending functionality. I wrote about the core structure in Specification-Driven Development: The Four Pillars.
Beyond traceability, we lean on three additional principles:
DRY (Don't Repeat Yourself). An agent that finds information in the first source it encounters will use it immediately. It won't check if the code is outdated. It trusts whatever it finds. This is what causes maintainability to collapse at the earlier levels.
Deterministic tools. L3 practices, elevated to a principle. Everything that can be handed to deterministic logic must be. Tools guarantee predictability and reproducibility. This matters in large codebases, and it matters for teams.
Context parsimony. If an instruction can be conveyed in three words instead of four without losing quality, do it in three. We initially added parsimony as a secondary principle. It's becoming the foundational one. The other three serve it. More on this in Principle of Parsimony in Context Engineering.
How many teams are here? No survey measures SDD adoption directly. If 30-48% use agents (Stack Overflow, JetBrains data from above), and most are at L3, the fraction doing systematic spec-driven work is small. My estimate: around 10%.
L5. Autonomous agents
I only know about these systems in theory. Colleague stories at conferences, hallway conversations, CTO mailing lists. Tools like Codegen (tag @codegen in a Linear issue and it ships a PR) are making this more accessible. Task trackers are adding first-class agent support.
I believe at least some of these claims are genuine. We're fairly close ourselves.
What happens here: the specialist (I prefer Product Engineer over "developer" at this point) doesn't open Claude, Cursor, or any IDE in daily work. They create tickets in a task tracker with API access for agents. Linear, Jira, YouTrack, whatever has an API.
Agents pick up tickets and work. Design, develop, test, review. When they hit blockers, they flag it in the ticket, reassign to whoever's needed, and wait. Same SDD as L4, but without supervision during execution.
For the Product Engineer, it's the same interface a product manager uses with a dev team.
Why aren't we there yet? Security. Tasks require access to databases, clusters, servers, repositories. Leaving an agent alone with that demands serious safeguards. We're working through it. No doubt it's realistic. A matter of time.
How many teams are here? Less than 1%, by my estimate.
What to take away from this
If you're a developer: figure out which level you're at. You can't skip levels, but you can move through them faster once you see them as intermediate stops.
If you buy software development services: look at who you're working with. What counted as high qualification in 2024 has changed radically by 2026. By 2027, the old standards won't matter at all.